Certleader offers free demo for DP-201 exam. "Designing an Azure Data Solution", also known as DP-201 exam, is a Microsoft Certification. This set of posts, Passing the Microsoft DP-201 exam, will help you answer those questions. The DP-201 Questions & Answers covers all the knowledge points of the real exam. 100% real Microsoft DP-201 exams and revised by experts!
Online DP-201 free questions and answers of New Version:
NEW QUESTION 1
You need to recommend a backup strategy for CONT_SQL1 and CONT_SQL2. What should you recommend?
- A. Use AzCopy and store the data in Azure.
- B. Configure Azure SQL Database long-term retention for all databases.
- C. Configure Accelerated Database Recovery.
- D. Use DWLoader.
Answer: B
Explanation:
Scenario: The database backups have regulatory purposes and must be retained for seven years.
NEW QUESTION 2
A company is developing a mission-critical line of business app that uses Azure SQL Database Managed Instance. You must design a disaster recovery strategy for the solution.
You need to ensure that the database automatically recovers when full or partial loss of the Azure SQL Database service occurs in the primary region.
What should you recommend?
- A. Failover-group
- B. Azure SQL Data Sync
- C. SQL Replication
- D. Active geo-replication
Answer: A
Explanation:
Auto-failover groups is a SQL Database feature that allows you to manage replication and failover of a group of databases on a SQL Database server or all databases in a Managed Instance to another region (currently in public preview for Managed Instance). It uses the same underlying technology as active geo-replication. You can initiate failover manually or you can delegate it to the SQL Database service based on a user-defined policy.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-auto-failover-group
NEW QUESTION 3
You need to design a backup solution for the processed customer data. What should you include in the design?
- A. AzCopy
- B. AdlCopy
- C. Geo-Redundancy
- D. Geo-Replication
Answer: C
Explanation:
Scenario: All data must be backed up in case disaster recovery is required.
Geo-redundant storage (GRS) is designed to provide at least 99.99999999999999% (16 9's) durability of objects over a given year by replicating your data to a secondary region that is hundreds of miles away from
the primary region. If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn't recoverable. References:
https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
NEW QUESTION 4
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will use Azure SQL Data Warehouse as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Create a user-defined restore point before data is uploaded. Delete the restore point after data corruption checks complete.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: A
Explanation:
User-Defined Restore Points
This feature enables you to manually trigger snapshots to create restore points of your data warehouse before and after large modifications. This capability ensures that restore points are logically consistent, which provides additional data protection in case of any workload interruptions or user errors for quick recovery time.
Note: A data warehouse restore is a new data warehouse that is created from a restore point of an existing or deleted data warehouse. Restoring your data warehouse is an essential part of any business continuity and disaster recovery strategy because it re-creates your data after accidental corruption or deletion.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
NEW QUESTION 5
You need to recommend a solution for storing the image tagging data. What should you recommend?
- A. Azure File Storage
- B. Azure Cosmos DB
- C. Azure Blob Storage
- D. Azure SQL Database
- E. Azure SQL Data Warehouse
Answer: C
Explanation:
Image data must be stored in a single data store at minimum cost.
Note: Azure Blob storage is Microsoft's object storage solution for the cloud. Blob storage is optimized for storing massive amounts of unstructured data. Unstructured data is data that does not adhere to a particular data model or definition, such as text or binary data.
Blob storage is designed for: Serving images or documents directly to a browser. Storing files for distributed access. Streaming video and audio. Writing to log files. Storing data for backup and restore, disaster recovery, and archiving. Storing data for analysis by an on-premises or Azure-hosted service.
Serving images or documents directly to a browser. Storing files for distributed access. Streaming video and audio. Writing to log files. Storing data for backup and restore, disaster recovery, and archiving. Storing data for analysis by an on-premises or Azure-hosted service.
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-blobs-introduction
NEW QUESTION 6
You plan to migrate data to Azure SQL Database.
The database must remain synchronized with updates to Microsoft Azure and SQL Server. You need to set up the database as a subscriber.
What should you recommend?
- A. Azure Data Factory
- B. SQL Server Data Tools
- C. Data Migration Assistant
- D. SQL Server Agent for SQL Server 2021 or later
- E. SQL Server Management Studio 17.9.1 or later
Answer: E
Explanation:
To set up the database as a subscriber we need to configure database replication. You can use SQL Server Management Studio to configure replication. Use the latest versions of SQL Server Management Studio in order to be able to use all the features of Azure SQL Database.
References:
https://www.sqlshack.com/sql-server-database-migration-to-azure-sql-database-using-sql-server-transactionalrep
NEW QUESTION 7
You are designing an Azure Data Factory pipeline for processing data. The pipeline will process data that is stored in general-purpose standard Azure storage.
You need to ensure that the compute environment is created on-demand and removed when the process is completed.
Which type of activity should you recommend?
- A. Databricks Python activity
- B. Data Lake Analytics U-SQL activity
- C. HDInsight Pig activity
- D. Databricks Jar activity
Answer: C
Explanation:
The HDInsight Pig activity in a Data Factory pipeline executes Pig queries on your own or on-demand HDInsight cluster.
References:
https://docs.microsoft.com/en-us/azure/data-factory/transform-data-using-hadoop-pig
NEW QUESTION 8
A company has locations in North America and Europe. The company uses Azure SQL Database to support business apps.
Employees must be able to access the app data in case of a region-wide outage. A multi-region availability solution is needed with the following requirements: Read-access to data in a secondary region must be available only in case of an outage of the primary region. The Azure SQL Database compute and storage layers must be integrated and replicated together.
Read-access to data in a secondary region must be available only in case of an outage of the primary region. The Azure SQL Database compute and storage layers must be integrated and replicated together.
You need to design the multi-region high availability solution.
What should you recommend? To answer, select the appropriate values in the answer area.
NOTE: Each correct selection is worth one point.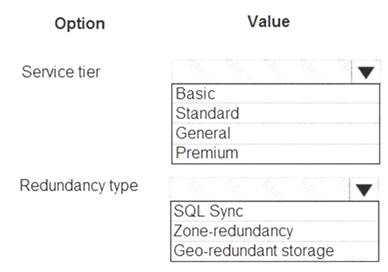
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Standard
The following table describes the types of storage accounts and their capabilities: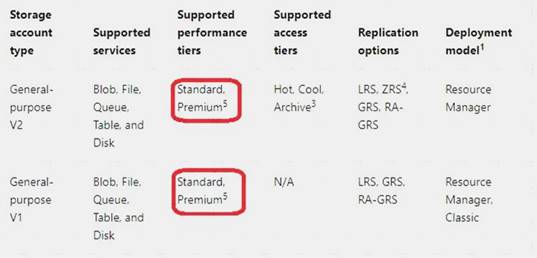
Box 2: Geo-redundant storage
If your storage account has GRS enabled, then your data is durable even in the case of a complete regional outage or a disaster in which the primary region isn't recoverable.
Note: If you opt for GRS, you have two related options to choose from:
GRS replicates your data to another data center in a secondary region, but that data is available to be read only if Microsoft initiates a failover from the primary to secondary region.
Read-access geo-redundant storage (RA-GRS) is based on GRS. RA-GRS replicates your data to another data center in a secondary region, and also provides you with the option to read from the secondary region. With RA-GRS, you can read from the secondary region regardless of whether Microsoft initiates a failover from the primary to secondary region.
References:
https://docs.microsoft.com/en-us/azure/storage/common/storage-introduction https://docs.microsoft.com/en-us/azure/storage/common/storage-redundancy-grs
NEW QUESTION 9
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company is developing a solution to manage inventory data for a group of automotive repair shops. The solution will use Azure SQL Data Warehouse as the data store.
Shops will upload data every 10 days.
Data corruption checks must run each time data is uploaded. If corruption is detected, the corrupted data must be removed.
You need to ensure that upload processes and data corruption checks do not impact reporting and analytics processes that use the data warehouse.
Proposed solution: Configure database-level auditing in Azure SQL Data Warehouse and set retention to 10 days.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Instead, create a user-defined restore point before data is uploaded. Delete the restore point after data corruption checks complete.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
NEW QUESTION 10
You need to design the unauthorized data usage detection system. What Azure service should you include in the design?
- A. Azure Databricks
- B. Azure SQL Data Warehouse
- C. Azure Analysis Services
- D. Azure Data Factory
Answer: B
NEW QUESTION 11
You are designing an Azure Databricks interactive cluster.
You need to ensure that the cluster meets the following requirements: Enable auto-termination
Retain cluster configuration indefinitely after cluster termination. What should you recommend?
- A. Start the cluster after it is terminated.
- B. Pin the cluster
- C. Clone the cluster after it is terminated.
- D. Terminate the cluster manually at process completion.
Answer: B
Explanation:
To keep an interactive cluster configuration even after it has been terminated for more than 30 days, an administrator can pin a cluster to the cluster list.
References:
https://docs.azuredatabricks.net/user-guide/clusters/terminate.html
NEW QUESTION 12
You are designing a real-time stream solution based on Azure Functions. The solution will process data uploaded to Azure Blob Storage.
The solution requirements are as follows:
New blobs must be processed with a little delay as possible. Scaling must occur automatically.
Costs must be minimized. What should you recommend?
- A. Deploy the Azure Function in an App Service plan and use a Blob trigger.
- B. Deploy the Azure Function in a Consumption plan and use an Event Grid trigger.
- C. Deploy the Azure Function in a Consumption plan and use a Blob trigger.
- D. Deploy the Azure Function in an App Service plan and use an Event Grid trigger.
Answer: C
Explanation:
Create a function, with the help of a blob trigger template, which is triggered when files are uploaded to or updated in Azure Blob storage.
You use a consumption plan, which is a hosting plan that defines how resources are allocated to your function app. In the default Consumption Plan, resources are added dynamically as required by your functions. In this serverless hosting, you only pay for the time your functions run. When you run in an App Service plan, you must manage the scaling of your function app.
References:
https://docs.microsoft.com/en-us/azure/azure-functions/functions-create-storage-blob-triggered-function
NEW QUESTION 13
You need to recommend the appropriate storage and processing solution? What should you recommend?
- A. Enable auto-shrink on the database.
- B. Flush the blob cache using Windows PowerShell.
- C. Enable Apache Spark RDD (RDD) caching.
- D. Enable Databricks IO (DBIO) caching.
- E. Configure the reading speed using Azure Data Studio.
Answer: C
Explanation:
Scenario: You must be able to use a file system view of data stored in a blob. You must build an architecture that will allow Contoso to use the DB FS filesystem layer over a blob store.
Databricks File System (DBFS) is a distributed file system installed on Azure Databricks clusters. Files in DBFS persist to Azure Blob storage, so you won’t lose data even after you terminate a cluster.
The Databricks Delta cache, previously named Databricks IO (DBIO) caching, accelerates data reads by creating copies of remote files in nodes’ local storage using a fast intermediate data format. The data is cached automatically whenever a file has to be fetched from a remote location. Successive reads of the same data are then performed locally, which results in significantly improved reading speed.
NEW QUESTION 14
You need to recommend an Azure SQL Database service tier. What should you recommend?
- A. Business Critical
- B. General Purpose
- C. Premium
- D. Standard
- E. Basic
Answer: C
Explanation:
The data engineers must set the SQL Data Warehouse compute resources to consume 300 DWUs. Note: There are three architectural models that are used in Azure SQL Database: General Purpose/Standard Business Critical/Premium Hyperscale
General Purpose/Standard Business Critical/Premium Hyperscale
NEW QUESTION 15
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure SQL Database that will use elastic pools. You plan to store data about customers in a table. Each record uses a value for CustomerID.
You need to recommend a strategy to partition data based on values in CustomerID. Proposed Solution: Separate data into shards by using horizontal partitioning.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: A
Explanation:
Horizontal Partitioning - Sharding: Data is partitioned horizontally to distribute rows across a scaled out data
tier. With this approach, the schema is identical on all participating databases. This approach is also called “sharding”. Sharding can be performed and managed using (1) the elastic database tools libraries or (2) selfsharding.
An elastic query is used to query or compile reports across many shards. References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-query-overview
NEW QUESTION 16
You are designing an Azure SQL Data Warehouse. You plan to load millions of rows of data into the data warehouse each day.
You must ensure that staging tables are optimized for data loading. You need to design the staging tables.
What type of tables should you recommend?
- A. Round-robin distributed table
- B. Hash-distributed table
- C. Replicated table
- D. External table
Answer: A
Explanation:
To achieve the fastest loading speed for moving data into a data warehouse table, load data into a staging table. Define the staging table as a heap and use round-robin for the distribution option.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/guidance-for-loading-data
NEW QUESTION 17
You are designing a data processing solution that will run as a Spark job on an HDInsight cluster. The solution will be used to provide near real-time information about online ordering for a retailer.
The solution must include a page on the company intranet that displays summary information. The summary information page must meet the following requirements: Display a summary of sales to date grouped by product categories, price range, and review scope. Display sales summary information including total sales, sales as compared to one day ago and sales as compared to one year ago. Reflect information for new orders as quickly as possible. You need to recommend a design for the solution.
What should you recommend? To answer, select the appropriate configuration in the answer area.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: DataFrame
DataFrames
Best choice in most situations.
Provides query optimization through Catalyst. Whole-stage code generation.
Direct memory access.
Low garbage collection (GC) overhead.
Not as developer-friendly as DataSets, as there are no compile-time checks or domain object programming. Box 2: parquet
The best format for performance is parquet with snappy compression, which is the default in Spark 2.x. Parquet stores data in columnar format, and is highly optimized in Spark.
NEW QUESTION 18
You need to design the image processing solution to meet the optimization requirements for image tag data. What should you configure? To answer, drag the appropriate setting to the correct drop targets.
Each source may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Tagging data must be uploaded to the cloud from the New York office location.
Tagging data must be replicated to regions that are geographically close to company office locations.
NEW QUESTION 19
HOTSPOT
You need to ensure that security policies for the unauthorized detection system are met. What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: Blob storage
Configure blob storage for audit logs.
Scenario: Unauthorized usage of the Planning Assistance data must be detected as quickly as possible. Unauthorized usage is determined by looking for an unusual pattern of usage.
Data used for Planning Assistance must be stored in a sharded Azure SQL Database. Box 2: Web Apps
SQL Advanced Threat Protection (ATP) is to be used.
One of Azure’s most popular service is App Service which enables customers to build and host web applications in the programming language of their choice without managing infrastructure. App Service offers auto-scaling and high availability, supports both Windows and Linux. It also supports automated deployments from GitHub, Visual Studio Team Services or any Git repository. At RSA, we announced that Azure Security Center leverages the scale of the cloud to identify attacks targeting App Service applications.
References:
https://azure.microsoft.com/sv-se/blog/azure-security-center-can-identify-attacks-targeting-azure-app-service-ap
NEW QUESTION 20
You plan to use an Azure SQL data warehouse to store the customer data. You need to recommend a disaster recovery solution for the data warehouse. What should you include in the recommendation?
- A. AzCopy
- B. Read-only replicas
- C. AdICopy
- D. Geo-Redundant backups
Answer: D
Explanation:
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/backup-and-restore
NEW QUESTION 21
A company stores data in multiple types of cloud-based databases.
You need to design a solution to consolidate data into a single relational database. Ingestion of data will occur at set times each day.
What should you recommend?
- A. SQL Server Migration Assistant
- B. SQL Data Sync
- C. Azure Data Factory
- D. Azure Database Migration Service
- E. Data Migration Assistant
Answer: C
Explanation:
https://docs.microsoft.com/en-us/azure/data-factory/introduction
https://azure.microsoft.com/en-us/blog/operationalize-azure-databricks-notebooks-using-data-factory/ https://azure.microsoft.com/en-us/blog/data-ingestion-into-azure-at-scale-made-easier-with-latest-enhancements
NEW QUESTION 22
You are designing an application. You plan to use Azure SQL Database to support the application.
The application will extract data from the Azure SQL Database and create text documents. The text documents will be placed into a cloud-based storage solution. The text storage solution must be accessible from an SMB network share.
You need to recommend a data storage solution for the text documents. Which Azure data storage type should you recommend?
- A. Queue
- B. Files
- C. Blob
- D. Table
Answer: B
Explanation:
Azure Files enables you to set up highly available network file shares that can be accessed by using the standard Server Message Block (SMB) protocol.
References:
https://docs.microsoft.com/en-us/azure/storage/common/storage-introduction https://docs.microsoft.com/en-us/azure/storage/tables/table-storage-overview
NEW QUESTION 23
A company is evaluating data storage solutions.
You need to recommend a data storage solution that meets the following requirements: Minimize costs for storing blob objects.
Optimize access for data that is infrequently accessed. Data must be stored for at least 30 days.
Data availability must be at least 99 percent. What should you recommend?
- A. Premium
- B. Cold
- C. Hot
- D. Archive
Answer: B
Explanation:
Azure’s cool storage tier, also known as Azure cool Blob storage, is for infrequently-accessed data that needs to be stored for a minimum of 30 days. Typical use cases include backing up data before tiering to archival systems, legal data, media files, system audit information, datasets used for big data analysis and more.
The storage cost for this Azure cold storage tier is lower than that of hot storage tier. Since it is expected that the data stored in this tier will be accessed less frequently, the data access charges are high when compared to hot tier. There are no additional changes required in your applications as these tiers can be accessed using
APIs in the same manner that you access Azure storage. References:
https://cloud.netapp.com/blog/low-cost-storage-options-on-azure
NEW QUESTION 24
......
100% Valid and Newest Version DP-201 Questions & Answers shared by Certifytools, Get Full Dumps HERE: https://www.certifytools.com/DP-201-exam.html (New 74 Q&As)
