We provide 70-775 Exam Questions in two formats. Download PDF & Practice Tests. Pass Microsoft 70-775 Exam quickly & easily. The 70-775 PDF type is available for reading and printing. You can print more and practice many times. With the help of our 70-775 Braindumps product and material, you can easily pass the 70-775 exam.
Online Microsoft 70-775 free dumps demo Below:
NEW QUESTION 1
Note: This question is part of a series of questions that present the same Scenario. Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You are implementing a batch processing solution by using Azure HDInsight.
You plan to import 300 TB of data.
You plan to use one job that has many concurrent tasks to import the data in memory.
You need to maximize the amount of concurrent tanks for the job.
What should you do?
- A. Use a shuffle join in an Apache Hive query that stores the data in a JSON format.
- B. Use a broadcast join in an Apache Hive query that stores the data in an ORC format.
- C. Increase the number of spark.executor.cores in an Apache Spark job that stores the data in a text format.
- D. Increase the number of spark.executor.instances in an Apache Spark job that stores the data in a text format.
- E. Decrease the level of parallelism in an Apache Spark job that Mores the data in a text format.
- F. Use an action in an Apache Oozie workflow that stores the data in a text format.
- G. Use an Azure Data Factory linked service that stores the data in Azure Data lake.
- H. Use an Azure Data Factory linked service that stores the data In an Azure DocumentDB database.
Answer: C
Explanation: References: https://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobspart-2/
NEW QUESTION 2
You are configuring the Hive views on an Azure HDInsight cluster that is configured to use Kerberos.
You plan to use the YARN loos to troubleshoot a query that runs against Apache Hadoop. You need to view the method, the service, and the authenticated account used to run the query. Which method call should you view in the YARN logs?
- A. HQL
- B. WebHDFS
- C. HDFS C* API
- D. Ambari REST API
Answer: D
NEW QUESTION 3
Note: This question is part of a series of questions that present the same Scenario. Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You need to deploy a NoSQL database to an HDInsight cluster. You will manage the servers that host the database by using Remote Desktop. The database must use the key/value pair format in a columnar model.
What should you do?
- A. Use an Azure PowerShell Script to create and configure a premium HDInsight cluste
- B. Specify Apache Hadoop as the cluster type and use Linux as the operating System.
- C. Use the Azure portal to create a standard HDInsight cluste
- D. Specify Apache Spark as the cluster type and use Linux as the operating system.
- E. Use an Azure PowerShell script to create a standard HDInsight cluste
- F. Specify Apache HBase as the cluster type and use Windows as the operating system.
- G. Use an Azure PowerShell script to create a standard HDInsight cluste
- H. Specify Apache Storm as the cluster type and use Windows as the operating system.
- I. Use an Azure PowerShell script to create a premium HDInsight cluste
- J. Specify Apache HBase as the cluster type and use Windows as the operating system.
- K. Use an Azure portal to create a standard HDInsight cluste
- L. Specify Apache Interactive Hive as the cluster type and use Windows as the operating system.
- M. Use an Azure portal to create a standard HDInsight cluste
- N. Specify Apache HBase as the cluster type and use Windows as the operating system.
Answer: G
Explanation: References: https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hbase-overview
NEW QUESTION 4
Note: This question is part of a series of questions that present the same Scenario. Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You need to deploy an HDInsight cluster that will have a custom Apache Ambari configuration.
The cluster will be joined to a domain and must perform the following:
* Fast data analytics and cluster computing by using in memory processing.
* Interactive queries and micro-batch stream processing What should you do?
- A. Use an Azure PowerShell Script to create and configure a premium HDInsight cluste
- B. Specify Apache Hadoop as the cluster type and use Linux as the operating System.
- C. Use the Azure portal to create a standard HDInsight cluste
- D. Specify Apache Spark as the cluster type and use Linux as the operating system.
- E. Use an Azure PowerShell script to create a standard HDInsight cluste
- F. Specify Apache HBase as the cluster type and use Windows as the operating system.
- G. Use an Azure PowerShell script to create a standard HDInsight cluste
- H. Specify Apache Storm as the cluster type and use Windows as the operating system.
- I. Use an Azure PowerShell script to create a premium HDInsight cluste
- J. Specify Apache HBase as the cluster type and use Windows as the operating system.
- K. Use an Azure portal to create a standard HDInsight cluste
- L. Specify Apache Interactive Hive as the cluster type and use Windows as the operating system.
- M. Use an Azure portal to create a standard HDInsight cluste
- N. Specify Apache HBase as the cluster type and use Windows as the operating system
Answer: D
NEW QUESTION 5
You have on Apache Hive table that contains one billion rows.
You plan to use queries that will filter the data by using the WHERE clause. The values of the columns will be known only while the data loads into a Hive table.
You need to decrease the query runtime. What should you configure?
- A. static partitioning
- B. bucket sampling
- C. parallel execution
- D. dynamic partitioning
Answer: C
Explanation: References: https://www.qubole.com/blog/5-tips-for-efficient-hive-queries/
NEW QUESTION 6
Note: This question is part of a series of questions that present the same Scenario. Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You are building a security tracking solution in Apache Kafka to parse Security logs. The Security logs record an entry each time a user attempts to access an application. Each log entry contains the IP address used to make the attempt and the country from which the attempt originated.
You need to receive notifications when an IP address from outside of the United States is used to access the application.
Solution: Create two new consumers. Create a file import process to send messages. Start the producer.
Does this meet the goal?
- A. Yes
- B. No
Answer: B
NEW QUESTION 7
Note: This question is part of a series of questions that present the same Scenario. Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
Start of Repeated Scenario:
You are planning a big data infrastructure by using an Apache Spark Cluster in Azure HDInsight. The cluster has 24 processor cores and 512 GB of memory.
The Architecture of the infrastructure is shown in the exhibit: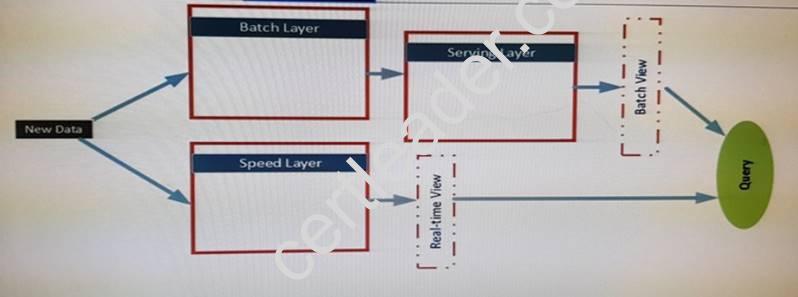
The architecture will be used by the following users:
* Support analysts who run applications that will use REST to submit Spark jobs.
* Business analysts who use JDBC and ODBC client applications from a real-time view. The business analysts run monitoring quires to access aggregate result for 15 minutes. The result will be referenced by subsequent quires.
* Data analysts who publish notebooks drawn from batch layer, serving layer and speed layer queries. All of the notebooks must support native interpreters for data sources that are bath processed. The serving layer queries are written in Apache Hive and must support multiple sessions. Unique GUIDs are used across the data sources, which allow the data analysts to use Spark SQL.
The data sources in the batch layer share a common storage container. The Following data sources are used:
* Hive for sales data
* Apache HBase for operations data
* HBase for logistics data by suing a single region server.
End of Repeated scenario.
You need to ensure that the support analysts can develop embedded analytics applications by using the least amount of development effort.
Which technology should you implement?
- A. Zeppelin
- B. Jupyter
- C. Apache Ambari
- D. Livy
Answer: D
Explanation: References: https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-apache-spark-livyrest-interface
NEW QUESTION 8
Note: This question is part of a series of questions that present the same Scenario. Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You are building a security tracking solution in Apache Kafka to parse Security logs. The Security logs record an entry each time a user attempts to access an application. Each log entry contains the IP address used to make the attempt and the country from which the attempt originated.
You need to receive notifications when an IP address from outside of the United States is used to access the application.
Solution: Create new topics. Create a file import process to send messages. Start the consumer and run the producer.
Does this meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION 9
You plan to copy data from Azure Blob storage to an Azure SQL database by using Azure Data factory. Which file formats can you use?
- A. binary, JSON, Apache Parquet, and ORC
- B. OXPS, binary, text and JSON
- C. XML, Apache Avro, text, and ORC
- D. text, JSON, Apache Avro, and Apache Parquet
Answer: D
Explanation: References: https://docs.microsoft.com/en-us/azure/data-factory/supported-file-formatsand-compression-codecs
NEW QUESTION 10
Note: This question is part of a series of questions that present the same Scenario. Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
You are implementing a batch processing solution by using Azure HDlnsight. You have a table that contains sales data.
You plan to implement a query that will return the number of orders by zip code.
You need to minimize the execution time of the queries and to maximize the compression level of the resulting data.
What should you do?
- A. Use a shuffle join in an Apache Hive query that stores the data in a JSON format.
- B. Use a broadcast join in an Apache Hive query that stores the data in an ORC format.
- C. Increase the number of spark.executor.cores in an Apache Spark job that stores the data in a text format.
- D. Increase the number of spark.executor.instances in an Apache Spark job that stores the data in a text format.
- E. Decrease the level of parallelism in an Apache Spark job that Mores the data in a text format.
- F. Use an action in an Apache Oozie workflow that stores the data in a text format.
- G. Use an Azure Data Factory linked service that stores the data in Azure Data lake.
- H. Use an Azure Data Factory linked service that stores the data In an Azure DocumentDBdatabase.
Answer: B
NEW QUESTION 11
You have an Apache Hadoop cluster in Azure HDInsiqht that has a head node and three data nodes. You have a MapReduce job.
You receive a notification that a data node failed.
You need to identity which component caused the failure. Which tool should you use?
- A. Job Tracker
- B. TaskTracker
- C. ResourceManager
- D. ApplicationMaster
Answer: C
NEW QUESTION 12
Note: This question is part of a series of questions that present the same Scenario. Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
Start of Repeated Scenario:
You have an initial data that contains the crime data from major cities.
You plan to build training models from the training data. You plan to automate the process of adding more data to the training models and to training the models by using the additional data, including data that is collected in near real time. The system will be used to analyze event data gathered from many different sources. Such as Internet of things (IoT) devices, Live video surveillance, and traffic activities, and to generate predictions of an increased crime risk at a particular time and ptace.
You have an incoming data stream from Twitter and an incoming data stream from
Facebook. which are event-based only, rather than time-based. You also have a time interval stream every 10 seconds.
The data is in a key/value pair format. The value field represents a number that defines how many times a hashtag occurs within a Facebook post or how many times a tweet that contains a specific hashtag is retweeted.
You must use the appropriate data storage, stream analytics techniques, and Azure HDInsight cluster types tor the various tasks associated to the processing pipeline.
End of repeated Scenario.
You plan to consolidate all of the stream into a single timeline, even though none of the streams report events at the same interval.
You need to aggregate the data from the feeds to align with the time interval stream. The result must be the sim of all values for each within a 10 second interval, with the keys being the hashtags.
Which function should you use?
- A. countByWindow
- B. reduccByWindow
- C. reduceByKeyAndWindow
- D. countByValueAndWindow
- E. updateStateByKey
Answer: E
NEW QUESTION 13
You have an Azure HDlnsight cluster.
You need to build a solution to ingest real-time streaming data into nonrelational distributed database.
What should you use to build the solution?
- A. Apatite Hive and Apache Kafka
- B. Spark and Phoenix
- C. Apache Storm and Apache HBase
- D. Apache Pig and Apache HCatalog
Answer: C
NEW QUESTION 14
Note: This question is part of a series of questions that present the same Scenario. Each question I the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution while others might not have correct solution.
Start of Repeated Scenario:
You have an initial data that contains the crime data from major cities.
You plan to build training models from the training data. You plan to automate the process of adding more data to the training models and to training the models by using the additional data, including data that is collected in near real time. The system will be used to analyze event data gathered from many different sources. Such as Internet of things (IoT) devices, Live video surveillance, and traffic activities, and to generate predictions of an increased crime risk at a particular time and ptace.
You have an incoming data stream from Twitter and an incoming data stream from Facebook. which are event-based only, rather than time-based. You also have a time interval stream every 10 seconds.
The data is in a key/value pair format. The value field represents a number that defines how many times a hashtag occurs within a Facebook post or how many times a tweet that contains a specific hashtag is retweeted.
You must use the appropriate data storage, stream analytics techniques, and Azure HDInsight cluster types tor the various tasks associated to the processing pipeline.
End of repeated Scenario.
You are planning a storage strategy for a large amount of analytic data used for the crime data analytics system. The initial data load involves aver 100 billion records, and more than two billion records will be added daily.
You already created an Apache Hadoop cluster in HDInsight premium.
You need to implement the storage strategy to meet the following requirements:
• The storage capacity must support 50 TB.
• The storage must he optimized tor Hadoop.
• The data must be stored in its native format
• Enterprise-level security based on Active Directory must be supported.
What should you create?
- A. a virtual machine (VM) by using the Window, that has premium storage- a G-series size, and uses Microsoft SQL Server 2021 to store the data
- B. an Azure Data Lake Analytics service by using Azure Power Shell
- C. an Azure Data Lake Store account by using the Azure portal
- D. an Azure Blob storage account by using the Azure portal
Answer: C
Explanation: References: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-getstarted-portal
NEW QUESTION 15
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You need to deploy an enterprise data warehouse that will support in-memory analytics. The data warehouse must support connections that use the Microsoft Hive ODBC Driver and Beeline. The data warehouse will be managed by using Apache Ambari only.
What should you do?
- A. Use an Azure PowerShell script to create and configure a premium HDInsight cluster.Specify Apache Hadoop as the cluster type and use Linux as the operating system.
- B. Use the Azure portal to create a standard HDInsight cluste
- C. Specify Apache Spark as the cluster type and use Linux as the operating system.
- D. Use an Azure PowerShell script to create a standard HDInsight cluste
- E. Specify Apache HBase as the cluster type and use Windows as the operating system.
- F. Use an Azure PowerShell script to create a standard HDInsight cluste
- G. Specify Apache Storm as the cluster type and use Windows as the operating system.
- H. Use an Azure PowerShell script to create a premium HDInsight cluste
- I. Specify Apache HBase as the cluster type and use Linux as the operating system.
- J. Use an Azure portal to create a standard HDInsight cluste
- K. Specify Apache Interactive Hive as the cluster type and use Linux as the operating system.
- L. Use an Azure portal to create a standard HDInsight cluste
- M. Specify Apache HBase as the cluster type and use Linux as the operating system.
Answer: F
Explanation: References: https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-useinteractive-hive
NEW QUESTION 16
DRAG DROP
You have a text file named Data/examples/product.txt that contains product information.
You need to create a new Apache Hive table, import the product information to the table, and then read the top 100 rows of the table.
Which four code segments should you use in sequence? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.
Answer:
Explanation:
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql(“CREATE TABLE IF NOT EXISTS productid INT, productname STRING)”
sqlContext.sql("LOAD DATA LOCAL INPATH ‘Data/examples/product.txt’ INTO TABLE
product")
sqlContext.sql("SELECT productid, productname FROM product LIMIT 100").collect().foreach (println)
References: https://www.tutorialspoint.com/spark_sql/spark_sql_hive_tables.htm
NEW QUESTION 17
DRAG DROP
You are evaluating the use of Azure HDInsight clusters for various workloads. Which type of HDInsight cluster should you create for each workloads?
Answer:
Explanation: https://www.blue-granite.com/blog/how-to-choose-the-right-hdinsight-cluster
NEW QUESTION 18
You have an Apache Spark cluster in Azure HDInsight. You plan to join a large table and a lookup table.
You need to minimize data transfers during the join operation. What should you do?
- A. Use the reduceByKey function
- B. Use a Broadcast variable.
- C. Repartition the data.
- D. Use the DISK_ONLY storage level.
Answer: B
100% Valid and Newest Version 70-775 Questions & Answers shared by Certleader, Get Full Dumps HERE: https://www.certleader.com/70-775-dumps.html (New 61 Q&As)
