It is impossible to pass Amazon-Web-Services DOP-C01 exam without any help in the short term. Come to Examcollection soon and find the most advanced, correct and guaranteed Amazon-Web-Services DOP-C01 practice questions. You will get a surprising result by our Avant-garde AWS Certified DevOps Engineer- Professional practice guides.
Amazon-Web-Services DOP-C01 Free Dumps Questions Online, Read and Test Now.
NEW QUESTION 1
Your company is planning to develop an application in which the front end is in .Net and the backend is in DynamoDB. There is an expectation of a high load on the application. How could you ensure the scalability of the application to reduce the load on the DynamoDB database? Choose an answer from the options below.
- A. Add more DynamoDB databases to handle the load.
- B. Increase write capacity of Dynamo DB to meet the peak loads
- C. Use SQS to assist and let the application pull messages and then perform the relevant operation in DynamoDB.
- D. Launch DynamoDB in Multi-AZ configuration with a global index to balance writes
Answer: C
Explanation:
When the idea comes for scalability then SQS is the best option. Normally DynamoDB is scalable, but since one is looking for a cost effective solution, the messaging in SQS can assist in managing the situation mentioned in the question.
Amazon Simple Queue Service (SQS) is a fully-managed message queuing service for reliably communicating among distributed software components and microservices - at any scale. Building applications from individual components that each perform a discrete function improves scalability and reliability, and is best practice design for modern applications. SQS makes it simple and cost- effective to decouple and coordinate the components of a cloud application. Using SQS, you can send, store, and receive messages between software components at any volume, without losing messages or requiring other services to be always available
For more information on SQS, please refer to the below URL:
• https://aws.amazon.com/sqs/
NEW QUESTION 2
What are the benefits when you implement a Blue Green deployment for your infrastructure or application level changes. Choose 3 answers from the options given below
- A. Nearzero-downtime release for new changes
- B. Betterrollback capabilities
- C. Abilityto deploy with higher risk
- D. Goodturnaround time for application deployments
Answer: ABD
Explanation:
The AWS Documentation mentions the following
Blue/green deployments provide near zero-downtime release and rollback capabilities. The fundamental idea behind blue/green deployment is to shift traffic between two identical environments that are running different versions of your application. The blue environment represents the current application version serving production traffic. In parallel, the green environment is staged running a different version of your application. After the green environment is ready and tested, production traffic is redirected from blue to green.
For more information on Blue Green deployments please see the below link:
• https://dOawsstatic.com/whitepapers/AWS_Blue_Green_Deployments.pdf
NEW QUESTION 3
You have a web application that is currently running on a three M3 instances in three AZs. You have an Auto Scaling group configured to scale from three to thirty instances. When reviewing your Cloud Watch metrics, you see that sometimes your Auto Scalinggroup is hosting fifteen instances. The web application is reading and writing to a DynamoDB.configured backend and configured with 800 Write Capacity Units and 800 Read Capacity Units. Your DynamoDB Primary Key is the Company ID. You are hosting 25 TB of data in your web application. You have a single customer that is complaining of long load times when their staff arrives at the office at 9:00 AM and loads the website, which consists of content that is pulled from DynamoDB. You have other customers who routinely use the web application. Choose the answer that will ensure high availability and reduce the customer's access times.
- A. Adda caching layer in front of your web application by choosing ElastiCacheMemcached instances in one of the AZs.
- B. Doublethe number of Read Capacity Units in your DynamoDB instance because theinstance isprobably being throttled when the customer accesses the website andyour web application.
- C. Changeyour Auto Scalinggroup configuration to use Amazon C3 instance types, becausethe web application layer is probably running out of compute capacity.
- D. Implementan Amazon SQS queue between your DynamoDB database layer and the webapplication layer to minimize the large burst in traffic the customergenerateswhen everyone arrives at the office at 9:00AM and begins accessing the website.
- E. Usedata pipelines to migrate your DynamoDB table to a new DynamoDB table with aprimary key that is evenly distributed across your datase
- F. Update your webappl ication to request data from the new table
Answer: E
Explanation:
The AWS documentation provide the following information on the best performance for DynamoDB tables
The optimal usage of a table's provisioned throughput depends on these factors: The primary key selection.
The workload patterns on individual items. The primary key uniquely identifies each item in a table. The primary key can be simple (partition key) or composite (partition key and sort key). When it stores data, DynamoDB divides a table's items into multiple partitions, and distributes the data primarily based upon the partition key value. Consequently, to achieve the full amount of request throughput you have provisioned for a table, keep your workload spread evenly across the partition key values. Distributing requests across partition key values distributes the requests across partitions. For more information on DynamoDB best practises please visit the link:
• http://docs.aws.a mazon.com/amazondynamodb/latest/developerguide/Guide I inesForTables.htm I
Note: One of the AWS forumns is explaining the steps for this process in detail. Based on that, while importing data from S3 using datapipeline to a new table in dynamodb we can create a new index. Please find the steps given below.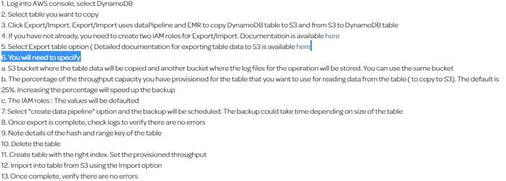
NEW QUESTION 4
You currently have an Auto Scaling group with an Elastic Load Balancer and need to phase out all instances and replace with a new instance type. What are 2 ways in which this can be achieved.
- A. Use Newest In stance to phase out all instances that use the previous configuration.
- B. Attach an additional ELB to your Auto Scaling configuration and phase in newer instances while removing older instances.
- C. Use OldestLaunchConfiguration to phase out all instances that use the previous configuratio
- D. V
- E. Attach an additional Auto Scaling configuration behind the ELB and phase in newer instances while removing older instances.
Answer: CD
Explanation:
When using the OldestLaunchConfiguration policy Auto Scaling terminates instances that have the oldest launch configuration. This policy is useful when you're
updating a group and phasing out the instances from a previous configuration.
For more information on Autoscaling instance termination, please visit the below URL: http://docs.aws.amazon.com/autoscaling/latest/userguide/as-instance-termination.html Option D is an example of Blue Green Deployments.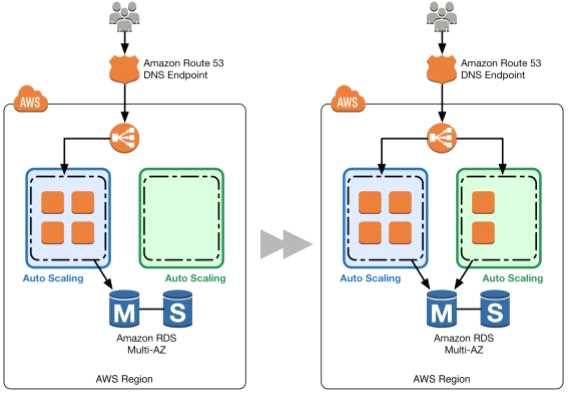
A blue group carries the production load while a green group is staged and deployed with the new code. When if s time to deploy, you simply attach the green group to the existing load balancer to introduce traffic to the new environment. For HTTP/HTTP'S listeners, the load balancer favors the green Auto Scaling group because it uses a least outstanding requests routing algorithm
As you scale up the green Auto Scaling group, you can take blue Auto Scaling group instances out of service by either terminating them or putting them in Standby state.
For more information on Blue Green Deployments, please refer to the below document link: from
AWS
• https://dOawsstatic.com/whitepapers/AWS_Blue_Green_Deployments.pdf
NEW QUESTION 5
You were just hired as a DevOps Engineer for a startup. Your startup uses AWS for 100% of their infrastructure. They currently have no automation at all for deployment, and they have had many failures while trying to deploy to production.The company has told you deployment process risk mitigation is the most important thing now, and you have a lot of budget for tools and AWS resources.
Their stack includes a 2-tier API with data stored in DynamoDB or S3, depending on type. The Compute layer is EC2 in Auto Scaling Groups. They use Route53 for DNS pointing to an ELB. An ELB balances load across the EC2 instances. The scaling group properly varies between 4 and 12 EC2 servers. Which of the following approaches, given this company's stack and their priorities, best meets the company's needs?
- A. Model the stack in AWS Elastic Beanstalk as a single Application with multiple Environment
- B. Use Elastic Beanstalk's Rolling Deploy option to progressively roll out application code changes when promoting across environments.
- C. Model the stack in three CloudFormation templates: Data layer, compute layer, and networking laye
- D. Write stack deployment and integration testing automation following Blue-Green methodologie
- E. •>/
- F. Model the stack in AWS OpsWorks as a single Stack, with 1 compute layer and its associated EL
- G. Use Chef and App Deployments to automate Rolling Deployment.
- H. Model the stack in 1 CloudFormation template, to ensure consistency and dependency graph resolutio
- I. Write deployment and integration testingautomation following Rolling Deployment methodologies.
Answer: B
Explanation:
Here you are using 2 of the best practices for deployment, one is Blue Green Deployments and the other is using Nested Cloudformation stacks.
The AWS Documentation mentions the below on nested stacks
As your infrastructure grows, common patterns can emerge in which you declare the same components in each of your templates. You can separate out these common components and create dedicated templates for them. That way, you can mix and match different templates but use nested stacks to create a single,
unified stack. Nested stacks are stacks that create other stacks. To create nested stacks, use the AWS::CloudFormation::Stackresource in your template to reference other templates.
For more information on Cloudformation best practises, please visit the link:
• http://docs.aws.amazon.com/AWSCIoudFormation/latest/UserGuide/best-practices. html For more information on Blue Green Deployment, please visit the link:
• https://dOawsstatic.com/whitepapers/AWS_Blue_Green_Deployments.pdf
NEW QUESTION 6
You've created a Cloudformation template as per your team's requets which is required for testing an application. By there is a request that when the stack is deleted, that the database is preserved for future reference. How can you achieve this using Cloudformation?
- A. Ensurethat the RDS is created with Read Replica's so that the Read Replica remainsafter the stack is torn down.
- B. IntheAWSCIoudFormation template, set the DeletionPolicy of theAWS::RDS::DBInstance'sDeletionPolicy property to "Retain."
- C. Inthe AWS CloudFormation template, set the WaitPolicy of the AWS::RDS::DBInstance'sWaitPolicy property to "Retain."
- D. Inthe AWS CloudFormation template, set the AWS::RDS::DBInstance'sDBInstanceClassproperty to be read-only.
Answer: B
Explanation:
With the Deletion Policy attribute you can preserve or (in some cases) backup a resource when its stack is deleted. You specify a DeletionPolicy attribute for each resource that you want to control. If a resource has no DeletionPolicy attribute, AWS Cloud Formation deletes the resource by default. Note that this capability also applies to update operations that lead to resources being removed.
For more information on Cloudformation Deletion policy, please visit the below URL:
◆ http://docs.aws.amazon.com/AWSCIoudFormation/latest/UserGuide/aws-attribute-deletionpolicy.html
NEW QUESTION 7
You are planning on using AWS Code Deploy in your AWS environment. Which of the below features of AWS Code Deploy can be used to Specify scripts to be run on each instance at various stages of the deployment process
- A. AppSpecfile
- B. CodeDeployfile
- C. Configfile
- D. Deploy file
Answer: A
Explanation:
The AWS Documentation mentions the following on AWS Code Deploy
An application specification file (AppSpec file), which is unique to AWS CodeDeploy, is a YAML- formatted file used to:
Map the source files in your application revision to their destinations on the instance. Specify custom permissions for deployed files.
Specify scripts to be run on each instance at various stages of the deployment process. For more information on AWS CodeDeploy, please refer to the URL: http://docs.aws.amazon.com/codedeploy/latest/userguide/application-specification-files.htmI
NEW QUESTION 8
You have a setup in AWS which consists of EC2 Instances sitting behind and ELB. The launching and termination of the Instances are controlled via an Autoscaling Group. The architecture consists of a MySQL AWS RDS database. Which of the following can be used to induce one more step towards a self-healing architecture for this design?
- A. EnableReadReplica'sfortheAWSRDSdatabase.
- B. EnableMulti-AZ feature for the AWS RDS database.
- C. Createone more ELB in another region forfault tolerance
- D. Createone more Autoscaling Group in another region forfault tolerance
Answer: B
Explanation:
The AWS documentation mentions the following
Amazon RDS Multi-AZ deployments provide enhanced availability and durability for Database (DB) Instances, making them a natural fit for production database workloads. When you provision a Multi- AZ DB Instance, Amazon RDS automatically creates a primary DB Instance and synchronously replicates the data to a standby instance in a different Availability Zone (AZ). Cach AZ runs on its own physically distinct, independent infrastructure, and is engineered to be highly reliable.
In case of an infrastructure failure, Amazon RDS performs an automatic failover to the standby (or to a read replica in the case of Amazon Aurora), so that you can resume database operations as soon as the failover is complete. Since the endpoint for your DB Instance remains the same after a failover, your application can resume database operation without the need for manual administrative intervention.
For more information on AWS RDS Multi-AZ, please refer to the below link:
◆ https://aws.amazon.com/rds/details/multi-az/
NEW QUESTION 9
You currently have an Autoscalinggroup that has the following settings Min capacity-2
Desired capacity - 2 Maximum capacity - 2
Your launch configuration has AMI'S which are based on the t2.micro instance type. The application running on these instances are now experiencing issues and you have identified that the solution is to change the instance type of the instances running in the Autoscaling Group.
Which of the below solutions will meet this demand.
- A. Change the Instance type in the current launch configuratio
- B. Change the Desired value of the Autoscaling Group to 4. Ensure the new instances are launched.
- C. Delete the current Launch configuratio
- D. Create a new launch configuration with the new instance type and add it to the Autoscaling Grou
- E. This will then launch the new instances.
- F. Make a copy the Launch configuratio
- G. Change the instance type in the new launch configuratio
- H. Attach that to the Autoscaling Group.Change the maximum and Desired size of the Autoscaling Group to 4. Once the new instances are launched, change the Desired and maximum size back to 2.
- I. Change the desired and maximum size of the Autoscaling Group to 4. Make a copy the Launch configuratio
- J. Change the instance type in the new launch configuratio
- K. Attach that to the Autoscaling Grou
- L. Change the maximum and Desired size of the Autoscaling Group to 2
Answer: C
Explanation:
You should make a copy of the launch configuration, add the new instance type. The change the Autoscaling Group to include the new instance type. Then change the Desired number of the Autoscaling Group to 4 so that instances of new instance type can be launched. Once launched, change the desired size back to 2, so that Autoscaling will delete the instances with the older configuration. Note that the assumption here is that the current instances are equally distributed across multiple AZ's because Autoscaling will first use the AZRebalance process to terminate instances.
Option A is invalid because you cannot make changes to an existing Launch configuration.
Option B is invalid because if you delete the existing launch configuration, then your application will not be available. You need to ensure a smooth deployment process.
Option D is invalid because you should change the desired size to 4 after attaching the new launch configuration.
For more information on Autoscaling Suspend and Resume, please visit the below URL: http://docs.aws.amazon.com/autoscaling/latest/userguide/as-suspend-resu me-processes.html
NEW QUESTION 10
Your CTO thinks your AWS account was hacked. What is the only way to know for certain if there was unauthorized access and what they did, assuming your hackers are very sophisticated AWS engineers and doing everything they can to cover their tracks?
- A. Use CloudTrail Log File Integrity Validation.
- B. Use AWS Config SNS Subscriptions and process events in real time.
- C. Use CloudTrail backed up to AWS S3 and Glacier.
- D. Use AWS Config Timeline forensics.
Answer: A
Explanation:
To determine whether a log file was modified, deleted, or unchanged after CloudTrail delivered it, you can use CloudTrail log file integrity validation. This feature is built using industry standard algorithms: SHA-256 for hashing and SHA-256 with RSA for digital signing. This makes it computationally infeasible to modify, delete or forge CloudTrail log files without detection. You can use the AWS CLI to validate the files in the location where CloudTrail delivered them
Validated log files are invaluable in security and forensic investigations. For example, a validated log file enables you to assert positively that the log file itself has not changed, or that particular user credentials performed specific API activity. The CloudTrail log file integrity validation process also lets you know if a log file has been deleted or changed, or assert positively that no log files were delivered to your account during a given period of time.
For more information on Cloudtrail log file validation, please visit the below URL:
http://docs.aws.a mazon.com/awscloudtrail/latest/userguide/cloudtrai l-log-file-validation- intro.html
NEW QUESTION 11
You are incharge of creating a Cloudformation template that will be used to spin our resources on demand for your Devops team. The requirement is that this cloudformation template should be able to spin up resources in different regions. Which of the following aspects of Cloudformation templates can help you design the template to spin up resources based on the region.
- A. Use mappings section in the Cloudformation template, so that based on the relevant region, the relevant resource can be spinned up.
- B. Use the outputs section in the Cloudformation template, so that based on the relevant region, the relevant resource can be spinned up.
- C. Use the parameters section in the Cloudformation template, so that based on the relevant region, the relevant resource can be spinned up.
- D. Use the metadata section in the Cloudformation template, so that based on the relevant region, the relevant resource can be spinned up.
Answer: A
Explanation:
The AWS Documentation mentions
The optional Mappings section matches a key to a corresponding set of named values. For example, if you want to set values based on a region, you can create a
mapping that uses the region name as a key and contains the values you want to specify for each specific region. You use the Fn::FindlnMap intrinsic function to
retrieve values in a map.
For more information on mappings please refer to the below link:
◆ http://docs.aws.amazon.com/AWSCIoudFormation/latest/UserGuide/mappings-section-structure.html
NEW QUESTION 12
You are designing a service that aggregates clickstream data in batch and delivers reports to subscribers via email only once per week. Data is extremely spikey, geographically distributed, high- scale, and unpredictable. How should you design this system?
- A. Use a large RedShift cluster to perform the analysis, and a fleet of Lambdas to perform recordinserts into the RedShift table
- B. Lambda will scale rapidly enough for the traffic spikes.
- C. Use a CloudFront distribution with access log delivery to S3. Clicks should be recorded as querystring GETs to the distributio
- D. Reports are built and sent by periodically running EMRjobs over the access logs in S3.C Use API Gateway invoking Lambdas which PutRecords into Kinesis, and EMR running Spark performing GetRecords on Kinesis to scale with spike
- E. Spark on EMR outputs the analysis to S3, which are sent out via email.D- Use AWS Elasticsearch service and EC2 Auto Scaling group
- F. The Autoscaling groups scale based on click throughput and stream into the Elasticsearch domain, which is also scalabl
- G. Use Kibana to generate reports periodically.
Answer: B
Explanation:
When you look at building reports or analyzing data from a large data set, you need to consider CMR because this service is built on the Hadoop framework which is used to processes large data sets.
The ideal approach to getting data onto CMR is to use S3. Since the Data is extremely spikey and geographically distributed, using edge locations via Cloudfront distributions is the best way to fetch the data.
Option A is invalid because RedShift is more of a petabyte storage cluster.
Option C is invalid because having both Kinesis and CMR for the job analysis is redundant. Option D is invalid because Elastic Search is not an option for processing records.
For more information on Amazon CMR, please visit the below URL:
• https://aws.amazon.com/emr/
NEW QUESTION 13
You have deployed an Elastic Beanstalk application in a new environment and want to save the current state of your environment in a document. You want to be able to restore your environment to the current state later or possibly create a new environment. You also want to make sure you have a restore point. How can you achieve this?
- A. Use CloudFormation templates
- B. Configuration Management Templates
- C. Saved Configurations
- D. Saved Templates
Answer: C
Explanation:
You can save your environment's configuration as an object in Amazon S3 that can be applied to other environments during environment creation, or applied to a running environment. Saved configurations are YAML formatted templates that define an environment's platform configuration, tier, configuration option settings,
and tags.
For more information on Saved Configurations please refer to the below link:
• http://docs.aws.a mazon.com/elasticbeanstalk/latest/dg/envi ronment-configuration- savedconfig.html
NEW QUESTION 14
Which of the following services can be used to implement DevOps in your company.
- A. AWS Elastic Beanstalk
- B. AWSOpswork
- C. AWS Cloudformation
- D. All of the above
Answer: D
Explanation:
All of the services can be used to implement Devops in your company
1) AWS Elastic Beanstalk, an easy-to-use service for deploying and scaling web applications and services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker on servers such as Apache, Nginx, Passenger, and I IS.
2) AWS Ops Works, a configuration management service that helps you configure and operate applications of all shapes and sizes using Chef
3) AWS Cloud Formation, which is an easy way to create and manage a collection of related AWS resources, provisioning and updating them in an orderly and predictable fashion.
For more information on AWS Devops please refer to the below link:
• http://docs.aws.amazon.com/devops/latest/gsg/welcome.html
NEW QUESTION 15
Which of the following design strategies is ideal when designing loosely coupled systems. Choose 2 answers from the options given below
- A. Having the web and worker roles running on the same set of EC2 Instances
- B. Having the web and worker roles running on separate EC2 Instances
- C. Using SNS to establish communication between the web and worker roles
- D. Using SQS to establish communication between the web and worker roles
Answer: BD
Explanation:
The below diagram shows the ideal design which uses SQS and separate environments for web and worker processes. The SQS queue manages the communication between the web and worker roles.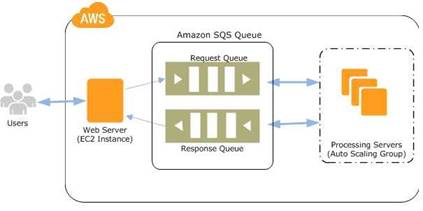
One example is the way Elastic beanstalk manages worker environments. For more information on
this, please visit the below URL:
◆ http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/using-features-managing-env-tiers.htmI
NEW QUESTION 16
What is required to achieve gigabit network throughput on EC2? You already selected cluster- compute, 10GB instances with enhanced networking, and your workload is already network-bound, but you are not seeing 10 gigabit speeds.
- A. Enable biplex networking on your servers, so packets are non-blocking in both directions and there's no switching overhead.
- B. Ensure the instances are in different VPCs so you don't saturate the Internet Gateway on any one VPC.
- C. Select PIOPS for your drives and mount several, so you can provision sufficient disk throughput.
- D. Use a placement group for your instances so the instances are physically near each other in the same Availability Zone.
Answer: D
Explanation:
A placement group is a logical grouping of instances within a single Availability Zone. Placement groups are recommended for applications that benefit from low network latency, high network throughput, or both. To provide the lowest latency, and the highest packet-per-second network performance for your placement group, choose an instance type that supports enhanced networking. For more information on Placement Groups, please visit the below URL: http://docs.aws.amazon.com/AWSCC2/latest/UserGuide/placement-groups.html
NEW QUESTION 17
Which of the following services can be used in conjunction with Cloudwatch Logs. Choose the 3 most viable services from the options given below
- A. Amazon Kinesis
- B. Amazon S3
- C. Amazon SQS
- D. Amazon Lambda
Answer: ABD
Explanation:
The AWS Documentation the following products which can be integrated with Cloudwatch logs
1) Amazon Kinesis - Here data can be fed for real time analysis
2) Amazon S3 - You can use CloudWatch Logs to store your log data in highly durable storage such as S3.
3) Amazon Lambda - Lambda functions can be designed to work with Cloudwatch log For more information on Cloudwatch Logs, please refer to the below link: link:http://docs^ws.amazon.com/AmazonCloudWatch/latest/logs/WhatlsCloudWatchLogs.html
NEW QUESTION 18
Which of the following are components of the AWS Data Pipeline service. Choose 2 answers from the options given below
- A. Pipeline definition
- B. Task Runner
- C. Task History
- D. Workflow Runner
Answer: AB
Explanation:
The AWS Documentation mentions the following on AWS Pipeline
The following components of AWS Data Pipeline work together to manage your data: A pipeline definition specifies the business logic of your data management.
A pipeline schedules and runs tasks. You upload your pipeline definition to the pipeline, and then activate the pipeline. You can edit the pipeline definition for a running pipeline and activate the pipeline again for it to take effect. You can deactivate the pipeline, modify a data source, and then activate the pipeline again. When you are finished with your pipeline, you can delete it.
Task Runner polls for tasks and then performs those tasks. For example. Task Runner could copy log files to Amazon S3 and launch Amazon EMR clusters. Task Runner is installed and runs automatically on resources created by your pipeline definitions. You can write a custom task runner application, or you can use the Task Runner application that is provided by AWS Data Pipeline.
For more information on AWS Pipeline, please visit the link: http://docs.aws.amazon.com/datapipeline/latest/DeveloperGuide/what-is-datapipeline.html
NEW QUESTION 19
One of your engineers has written a web application in the Go Programming language and has asked your DevOps team to deploy it to AWS. The application code is hosted on a Git repository.
What are your options? (Select Two)
- A. Create a new AWS Elastic Beanstalk application and configure a Go environment to host your application, Using Git check out the latest version of the code, once the local repository for Elastic Beanstalk is configured use "eb create" command to create an environment and then use "eb deploy" command to deploy the application.
- B. Writea Dockerf ile that installs the Go base image and uses Git to fetch yourapplicatio
- C. Create a new AWS OpsWorks stack that contains a Docker layer thatuses the Dockerrun.aws.json file to deploy your container and then use theDockerfile to automate the deployment.
- D. Writea Dockerfile that installs the Go base image and fetches your application usingGit, Create a new AWS Elastic Beanstalk application and use this Dockerfile toautomate the deployment.
- E. Writea Dockerfile that installs the Go base image and fetches your application usingGit, Create anAWS CloudFormation template that creates and associates an AWS::EC2::lnstanceresource type with an AWS::EC2::Container resource type.
Answer: AC
Explanation:
Opsworks works with Chef recipes and not with Docker containers so Option B and C are invalid. There is no AWS::CC2::Container resource for Cloudformation so Option D is invalid.
Below is the documentation on Clastic beanstalk and Docker
Clastic Beanstalk supports the deployment of web applications from Docker containers. With Docker containers, you can define your own runtime environment. You can choose your own platform, programming language, and any application dependencies (such as package managers or tools), that aren't supported by other platforms. Docker containers are self-contained and include all the configuration information and software your web application requires to run.
For more information on Clastic beanstalk and Docker, please visit the link: http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/create_deploy_docker.html
https://docs.aws.a mazon.com/elasticbeanstalk/latest/dg/eb-cl i3-getting-started.htmI https://docs^ws.amazon.com/elasticbeanstalk/latest/dg/eb3-cli-githtml
NEW QUESTION 20
You have a complex system that involves networking, 1AM policies, and multiple, three-tier applications. You are still receiving requirements for the new system, so you don't yet know how many AWS components will be present in the final design. You want to start using AWS CloudFormation to define these AWS resources so that you can automate and version-control your infrastructure. How would you use AWS CloudFormation to provide agile new environments for your customers in a cost-effective, reliable manner?
- A. Manually create one template to encompass all the resources that you need for the system, so you only have a single template to version-control.
- B. Create multiple separate templates for each logical part of the system, create nested stacks in AWS CloudFormation, and maintain several templates to version-contro
- C. •>/
- D. Create multiple separate templates for each logical part of the system, and provide the outputs from one to the next using an Amazon Elastic Compute Cloud (EC2) instance running the SDK forfinergranularity of control.
- E. Manually construct the networking layer using Amazon Virtual Private Cloud (VPC) because this does not change often, and then use AWS CloudFormation to define all other ephemeral resources.
Answer: B
Explanation:
As your infrastructure grows, common patterns can emerge in which you declare the same components in each of your templates. You can separate out these common components and create dedicated templates for them. That way, you can mix and match different templates but use nested stacks to create a single, unified stack. Nested stacks are stacks that create other stacks. To create nested stacks, use the AWS::CloudFormation::Stackresource in your template to reference other templates.
For more information on Cloudformation best practises please refer to the below link: http://docs.aws.amazon.com/AWSCIoudFormation/latest/UserGuide/best-practices.html
NEW QUESTION 21
You are planning on using encrypted snapshots in the design of your AWS Infrastructure. Which of the following statements are true with regards to EBS Encryption
- A. Snapshottingan encrypted volume makes an encrypted snapshot; restoring an encrypted snapshot creates an encrypted volume when specified / requested.
- B. Snapshotting an encrypted volume makes an encrypted snapshot when specified / requested; restoring an encrypted snapshot creates an encrypted volume when specified / requested.
- C. Snapshotting an encrypted volume makes an encrypted snapshot; restoring an encrypted snapshot always creates an encrypted volume.
- D. Snapshotting an encrypted volume makes an encrypted snapshot when specified / requested; restoring an encrypted snapshot always creates an encrypted volume.
Answer: C
Explanation:
Amazon CBS encryption offers you a simple encryption solution for your CBS volumes without the need for you to build, maintain, and secure your own key management infrastructure. When you create an encrypted CBS volume and attach it to a supported instance type, the following types of data are encrypted:
• Data at rest inside the volume
• All data moving between the volume and the instance
• All snapshots created from the volume
Snapshots that are taken from encrypted volumes are automatically encrypted. Volumes that are created from encrypted snapshots are also automatically
encrypted.
For more information on CBS encryption, please visit the below URL:
• http://docs.aws.amazon.com/AWSCC2/latest/UserGuide/ CBSCncryption.html
NEW QUESTION 22
Which of the following run command types are available for opswork stacks? Choose 3 answers from the options given below.
- A. UpdateCustom Cookbooks
- B. Execute Recipes
- C. Configure
- D. UnDeploy
Answer: ABC
NEW QUESTION 23
You have the requirement to get a snapshot of the current configuration of the resources in your AWS Account. Which of the following services can be used for this purpose
- A. AWS CodeDeploy
- B. AWS Trusted Advisor
- C. AWSConfig
- D. AWSIAM
Answer: C
Explanation:
The AWS Documentation mentions the following With AWS Config, you can do the following:
• Evaluate your AWS resource configurations for desired settings.
• Get a snapshot of the current configurations of the supported resources that are associated with your AWS account.
• Retrieve configurations of one or more resources that exist in your account.
• Retrieve historical configurations of one or more resources.
• Receive a notification whenever a resource is created, modified, or deleted.
• View relationships between resources. For example, you might want to find all resources that use a particular security group. For more information on AWS Config, please visit the below URL: http://docs.aws.amazon.com/config/latest/developerguide/WhatlsConfig.html
NEW QUESTION 24
Which of the following tools is available to send logdatafrom EC2 Instances.
- A. CloudWatch LogsAgent
- B. CloudWatchAgent
- C. Logsconsole.
- D. LogsStream
Answer: A
Explanation:
The AWS Documentation mentions the following
The CloudWatch Logs agent provides an automated way to send log data to Cloud Watch Logs from Amazon L~C2 instances. The agent is comprised of the following components:
A plug-in to the AWS CLI that pushes log data to CloudWatch Logs.
A script (daemon) that initiates the process to push data to CloudWatch Logs.
Acron job that ensures that the daemon is always running. For more information on Cloudwatch logs Agent, please see the below link:
http://docs.aws.a mazon.com/AmazonCloudWatch/latest/logs/AgentRefe re nee. htm I
NEW QUESTION 25
You are a Devops Engineer for your company. There is a requirement to log each time an Instance is scaled in or scaled out from an existing Autoscaling Group. Which of the following steps can be implemented to fulfil this requirement. Each step forms part of the solution.
- A. Createa Lambda function which will write the event to Cloudwatch logs
- B. Createa Cloudwatch event which will trigger the Lambda function.
- C. Createan SQS queue which will write the event to Cloudwatch logs
- D. Createa Cloudwatch event which will trigger the SQS queue.
Answer: AB
Explanation:
The AWS documentation mentions the following
You can run an AWS Lambda function that logs an event whenever an Auto Scaling group launches or terminates an Amazon CC2 instance and whether the launch or terminate event was successful.
For more information on configuring lambda with Cloudwatch events for this scenario, please visit the URL:
◆ http://docs.aws.amazon.com/AmazonCloudWatch/latest/events/LogASGroupState.html
NEW QUESTION 26
......
P.S. Easily pass DOP-C01 Exam with 116 Q&As Surepassexam Dumps & pdf Version, Welcome to Download the Newest Surepassexam DOP-C01 Dumps: https://www.surepassexam.com/DOP-C01-exam-dumps.html (116 New Questions)
